
Screaming Frog, my favourite, most used SEO Tool and I imagine the most used SEO tool in the industry. What would we do without it! (Remember using Xenu?)
There are some great guides on the different ways you can use it and the official site has a big amount of documentation on all the different settings, as there are a lot!
However, I haven’t seen a guide on what the best settings are for doing full site audits. Having trained people on using Screaming Frog since 2010, I know that new users struggle to understand what the best settings are for doing audits. Often missing issues due to the default settings.
The default settings applied on install aren’t sufficient for doing a full audit and need to be tweaked to get best results. Having used Screaming Frog since its release in 2010, I’m pretty sure I’ve nailed probably the best settings for most site audits.
The following is a guide on these settings. I’ll explain what I change over the default settings and also explain the reasoning behind my choices.
I’ve added screenshots for many of the settings and coloured the ticks green where I tick boxes over the default settings.
This isn’t a guide to every single setting in the tool, only the ones I change over default. So, for any settings not mentioned, I suggest keeping the default settings.
Jump to Section
System
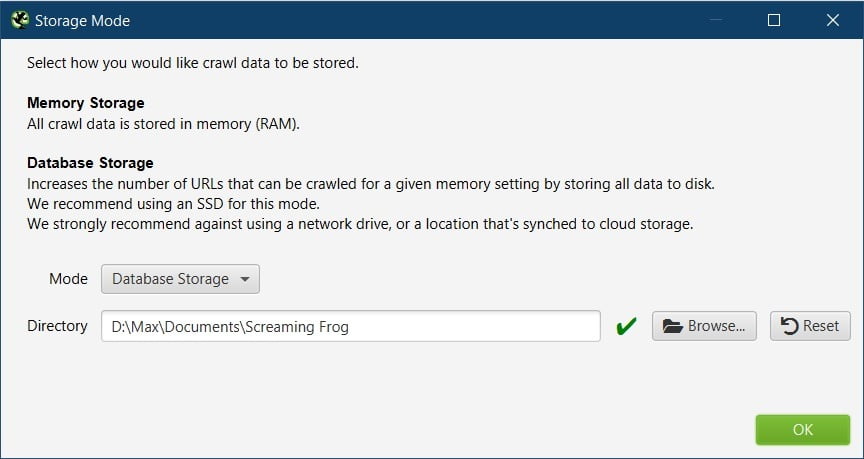
Storage Mode
In Screaming Frog, there are 2 options for how the crawl data will be processed and saved.
Via RAM, or storage on your hard drive.
Memory Storage
The RAM setting is the default setting and is recommended for sites under 500 URLs and machines that don’t have an SSD.
Using RAM mode can limit your crawls, because larger sites = more URLs and info to be stored.
As more RAM gets used up, your computer gets slower, SF gets slower and you may run out of memory and be unable to finish the crawl.
Also, when the size of a crawl gets very large, using Screaming Frog may start to get unwieldy. It may crash and the UI may slow down so much it’s almost unusable.
Database Storage
The 2nd mode, Database Storage, uses your hard drive to create a database where all the information will be stored.
The Database storage mode is recommended for machines that have an SSD and for crawling sites at scale.
As Screaming Frog has to write information continually to the database on your hard drive, it’s recommended to use only with an SSD. If you use it with a mechanical HDD, it would be much slower.
In the official guides, it’s mentioned the RAM setting can be quicker than Database mode.
Although after switching to the database storage mode I didn’t notice a reduction in crawling speed.
If you have an SSD, I’d recommend using Storage mode for all crawls even if under 500 URLs, for two reasons:
1. Continuous backup. In Database mode, Screaming Frog is continually saving to the database as it crawls. So, if Screaming Frog or your machine crashes, or you shut down by accident without saving, the crawl is autosaved.
In Memory mode, you have to manually save every time.
2. Less resource heavy on machines generally speaking, in Database mode I find it doesn’t hog up resources on my laptop too much.
Meaning, if I’m crawling and doing other work (which is most of the time!) my laptop doesn’t slow down as easily as it would when using up lots of RAM.
The official guide goes into a lot more detail about the different modes, which you can find here: https://www.screamingfrog.co.uk/seo-spider/user-guide/configuration/#storage
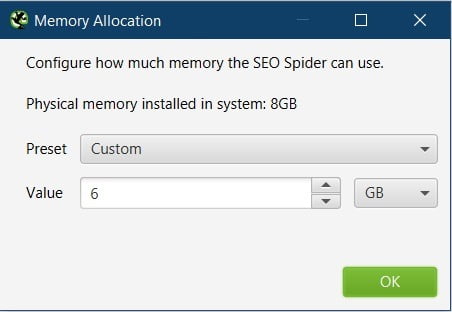
Memory Allocation
The Frog needs RAM to run, especially running it in RAM mode, but even in Storage mode the more RAM the better.
By default, it will have allocated 1GB in 32-bit machines and 2GB in 64-bit machines.
As per the official recommendation, I set 2GB below my machine’s max RAM. So, if I have 8GB RAM, I’ll allocate 6GB.
I used to allocate all but 1GB of my available RAM. However, I was having issues once and after contacting support they told me off and to leave 2GB for my machine!
Spider Settings
Crawl Tab
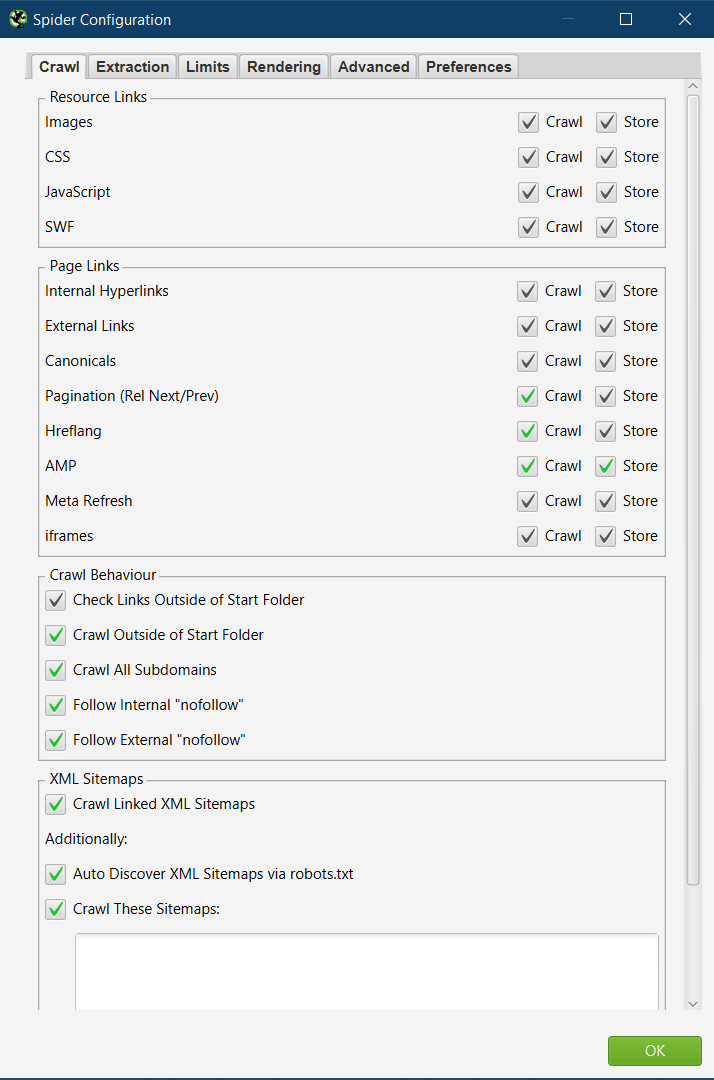
Page Links
By default, there are 4 boxes unticked here that I tick:
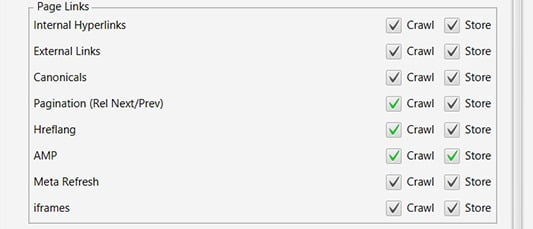
Pagination (Rel/Prev).
Although Google has stated they no longer support rel=next/pre links, we still want the Frog to crawl these and store them.
The reason being, there could be paginated pages that are only linked via these elements and not in the HTML body of the page.
This can happen if a site is using JavaScript for pagination links, or infinite scroll and the URLs aren’t included in XML sitemaps.
In that situation, If we don’t tick the box to crawl rel=next/pre links, it means there could be many URLs that aren’t found by the Frog and we aren’t made aware of.
There could be product pages only linked from paginated category pages for eCommerce sites, or articles for publisher sites.
Href lang.
If there are alternate versions of URLs for different languages/locales we want to ensure we discover them all in the crawl so we can properly audit them.
There could be a situation where the alternate version of URLs aren’t linked in the HTML body of the page.
Such as only being linked in a JS language menu, or the entire site being rendered by JavaScript but missing ahrefs for some internal links.
With this setting ticked, we will find URLs if they are only linked in Href lang tags. Especially important when auditing sites for international SEO.
AMP.
If a site is using AMP and you forgot to tick it, you’ll miss all the amp data and issues the Frog will gather. (Which is loads by the way!) https://www.screamingfrog.co.uk/how-to-audit-validate-amp/
A site could also be using AMP, but you aren’t aware that is it. This is easier to miss now since Google stopped showing the AMP icon in the SERPs.
Also for some unknown reason, my phone doesn’t load AMP versions of sites. So unless I see the AMP tag in the source code, or the tab populate in Screaming Frog, I won’t know a site is using AMP.
Crawl Behaviour
By default, there are 4 boxes unticked here that I tick:
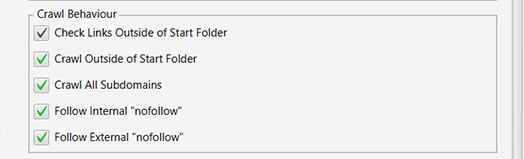
Crawl Outside of Start Folder.
Ticking this setting instructs the Frog to crawl outside of a folder it stated in.
E.g
if you started to crawl from https://example/blog/ and the Frog found links on pages within that folder to https://example/events, it will crawl URLs within that folder (and any other folders).
I presume if starting a crawl from a site’s root (https://example/) even without this setting ticked it will crawl all deeper folders. However, I have it ticked anyway just to ensure it crawls the entire site.
The only time I would untick it is if I’m limiting the crawl to just within a single subfolder.
Crawl All Subdomains.
Similar to the above, but leaving this unticked it won’t crawl any subdomains the Frog my encounter linked.
E.g
If you start the crawl from https://example/ and there are links to https://blog.events.com it won’t crawl that subdomain by default.
I always have this ticked, because if I’m doing a complete audit of a site, I also want to know about any subdomains there may be.
Follow Internal “nofollow”.
I click this because I want to discover as many URLs as possible to ensure I’m doing a thorough site audit.
Although tests have shown Google won’t crawl links with rel=”nofollow” tags, even if URLs are linked from one page with nofollow, they could be linked from other pages without it.
These could either be internal or external links or links in XML sitemaps.
So using rel=”nofollow” is not a way to control if a page can be crawled/indexed.
Also, I want to know if a site is using rel=”nofollow” so I can investigate and understand why they are using it on internal links. In most cases, I do not recommend using rel=”nofollow” internally.
Follow External “nofollow”.
Similar to above, I want the Frog to crawl all possible URLs, so I tick this option.
If I keep this unticked, we might miss external URLs which are 404s (no biggie for SEO, but bad UX) or miss discovering internal pages that are participating in link spam, or have been hacked.
XML Sitemaps
By default all 3 options in this section are unticked and I tick them all:

Crawl Linked XML Sitemaps.
As I keep mentioning, when auditing a site I want to discover as many URLs as possible.
If I don’t tick this box, then I won’t discover any URLs that are only linked to via XML Sitemaps.
This is one way to find orphan URLs (live, accessible URLs, that aren’t physically linked from other pages). There can be various reasons why URLs may become orphaned: Old pages, development pages, campaign pages, or simply an error and they should be linked via other pages.
It’s important to audit orphan URLs to understand if these pages should be removed if they aren’t valid pages, or if they are important pages that are missing internal links.
Auto Discover XML Sitemaps via robots.txt
Ticking this box instructs the Frog to automatically crawl the XML sitemaps linked in the robots.txt file.
As many sites include a link to their XML sitemaps here, it’s a no brainer to click this, so you don’t have to manually add the Sitemap URL below.
Crawl These Sitemaps.
Additionally, you can instruct the Frog to crawl certain XML sitemaps. (These can be XML index files or normal XML sitemap files).
This is useful if the sitemaps aren’t included in the robots.txt files.
Quick tips on finding XML sitemap URLs:
- Ask the owner of the site for them!
- Check in Google Search Console (other Webmaster Tools are available!) if they are submitted there.
You should ways ask for GSC access when doing an audit. - Do a search in Google for site:example.com inurl:xml
(If there are no results, it doesn’t mean there aren’t any sitemaps, just that none are indexed, which is quite often. But if all other methods fail, this is your last resort.)
All my crawl settings below:
Extraction Tab
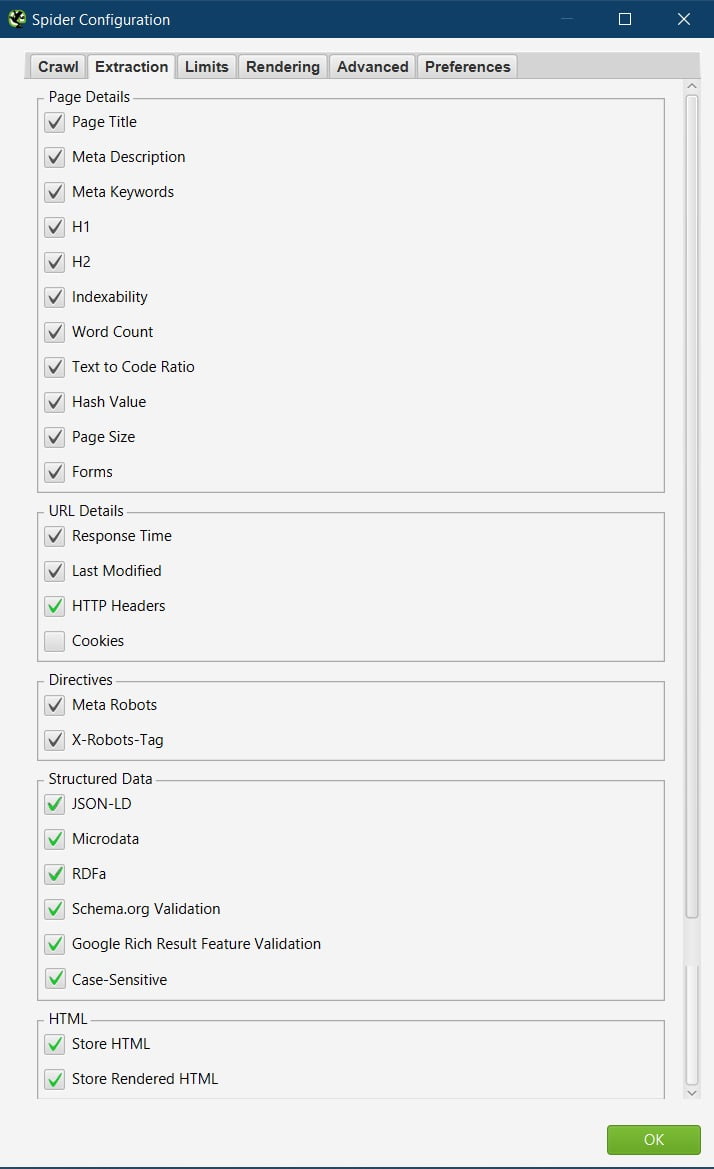
Page Details
By default, all these elements are ticked and that’s how I recommend you keep them for most audits, as these are all elements we want to check.
URL Details
I tick one option here over the default settings:

HTTP Headers.
Two main things I’m looking for in HTTP headers:
a. If a site is using dynamic serving of content for desktop vs mobile, it should use the Vary HTTP Header.
So I want to check if it’s using it, otherwise Google may have issues finding the mobile/desktop version of the content.
b. Google Web Light is a service by Google that converts web pages into smaller, faster pages optimised for slow internet connection.
You can see if a site is getting traffic from Web light in Google Search Console under Search Appearance.
The issue with Web Light is, when it automatically converts pages into a more optimised form, many features don’t work. I’ve worked with eCommerce sites where you cannot purchase anything on the Web Light version.
Therefore, if I see Web Light traffic in GSC, I’ll test the site in Web Light mode. If it doesn’t work correctly we can opt-out of it using by adding the Cache-Control: no-transform HTTP header, if it hasn’t already.
Structured Data
All the elements in this section are unticked by default, I tick them all:

JSON-LD
Microdata
RDFa
I tick all of the above options, so I can fully audit the schema of the site, no matter which way it’s implemented.
Schema.org Validation.
A great feature here they have implemented to check all schema to ensure it validates against the official suggested implementation.
Google Rich Results Feature Validation.
Another great feature that validates the mark-up against Google’s own documentation.
Select both options here, as Google has some specific requirements that aren’t included in the schema.org guidelines and the Schema.org guides cover a wider range than Google’s does.
These options make auditing schema so much easier. However, you should still manually check the schema implementation, to make sure it isn’t spammy and is being used on the correct page types in the way required by Google.
Case-Sensitive
I tick this, as some elements of Schema-mark up are required to use the correct case.
HTML
Both the options in this section are unticked by default, I always tick them:

Store HTML. When ticked, The Frog will save the HTML for every page.
This is extremely useful for double-checking any elements Frog reports on.
Sometimes The Frog may report on something, but when you check the page in your browser you cannot find the same element.
This can happen if the page has changed between the time of crawling and manually checking the page, if the page content is changed based on user-agent, or some sneaky cloaking or redirects are going on.
Also useful when auditing JavaScript render vs server render.
Store Rendered HTML.
When ticked, this will save the HTML that has been rendered by the Frog.
This is useful when auditing JavaScript sites to see the difference between the HTML code sent from the server and what is actually rendered client-side in the browser.
Viewing the ‘stored HTML’ vs viewing the ‘Rendered HTML’ is the same as the difference between pressing Ctrl U and viewing the HTML in chrome and right-clicking and inspecting in chrome.
All my extraction settings below:
Limits Tab
Max Redirects to Follow.
This is the only option I change for most crawls in this tab. It’s set to 5 by default, but I change it to the maximum, 20.
I do this as I have come across many sites that have really long redirect chains.
Setting the maximum helps me find the final destination in most redirect chains. I can then report in the audit that the chain should be broken and redirects should link to their final destination in a single hop.
You can change the other settings in this section as you see fit depending on the specific type of crawl, or size of the site you are dealing with.
Google luck with venturing over 5 million URLs young Padawan!

Rendering Tab
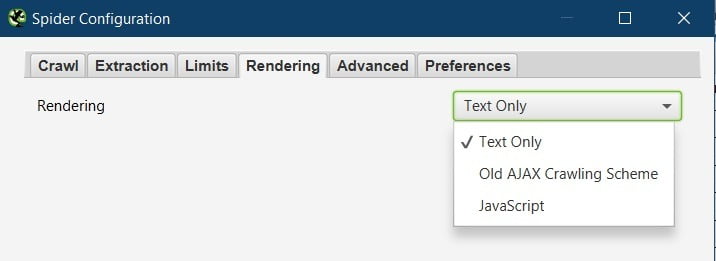
Here we can select how the Frog renders the site and what version of the HTML code it will crawl.
Text Only.
The Frog Crawls and renders the raw HTML as sent from the server. The same code you would see if you press ctrl+U and view source.
This setting is used for the majority of crawls unless the site is a full JavaScript site, in which case we might want to choose the JavaScript setting as below (but not always).
JavaScript.
The Frog will execute client-side rendered JavaScript and crawl the HTML code served from that. This could be very different to what you see when viewing the source.
If you are auditing a JavaScript (JS) site you may want to crawl with this setting on. However, not in all instances.
If you know a site is already using Server Side Rendering (SSR) or some pre-render solution, it can be better to crawl it as Text only to get a better understanding of what Googlebot may render.
If you’re auditing a JS site that isn’t using any SSR, you may want to crawl the site via both ways. Once as Text only and again as Javascript.
You can then compare the differences between the two crawls to see if any essential elements or URLs aren’t being included in the code in the JS version.
(Using Screaming Frog’s great crawl compare feature!)
Even though Google did say in the past they can render JS sites fine, they have since published these guidelines which suggest they aren’t so great at rendering it after all.
Speaking from experience, JS sites can cause Google countless issues with rendering, indexing and ranking content. Not to mention other search engines which cannot render JS.
I recommend SSR in nearly all cases for JS sites.
Old AJAX Crawling Scheme.
This is a now deprecated recommendation from Google to make AJAX-based websites crawlable.
You can use JavaScript rendering in most cases where this would have been used before.
Advanced Tab
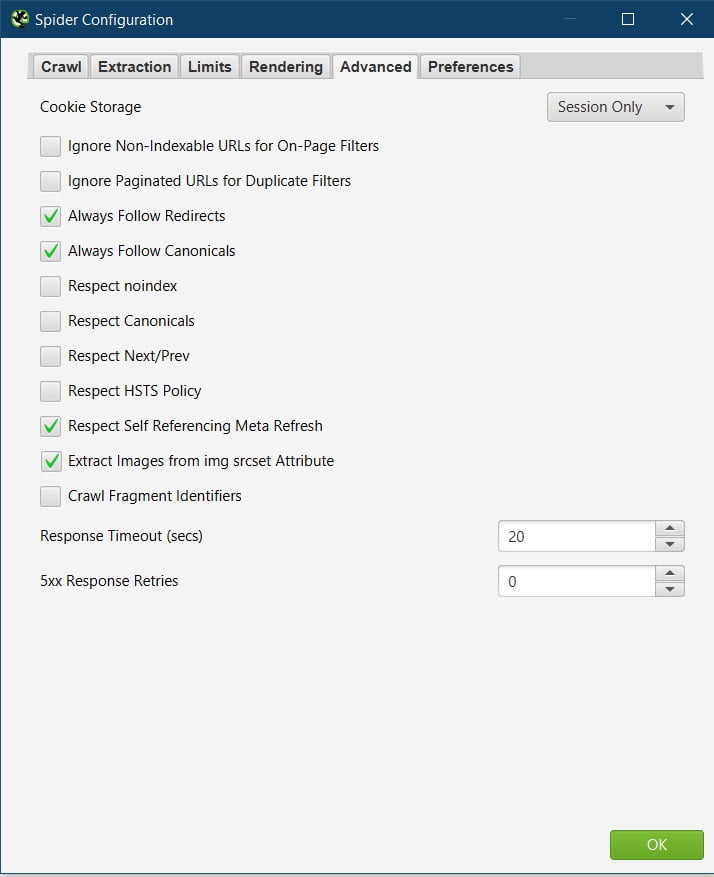
In this settings tab, I tick as well as untick a few boxes from the default settings:
Ignore Non-indexable URLs for On-Page Filters
![]()
This is ticked by default, however, I like to untick these options.
Even if a page is already non-indexable (non-indexable in Screaming Frogs case meaning it’s set to noindex or is canonicalised to a different URL) I still want to see if there are issues with any of the page’s elements.
Such as Page Titles, Meta Description, Meta Keywords, H1 and H2 tabs.
Why? Because there are often times where pages have been set to noindex or canonicalised, but this has been done in error.
(This is something you should always check in audits, are page’s indexability status actually set correctly?)
If I identify pages that are actually supposed to be indexed, then I still need to know if there are any issues with their page elements.
So when I come to create a report, I can say something like “xxx pages should have the noindex tag removed, as they should be indexed, additionally, they also have a list of xxxx issues that should be fixed.”
One caveat here though.
With this unticked, it means that non-indexable pages will show up as duplicates for Page Titles, Meta Description, Meta Keywords, H1 and H2 tabs.
So don’t blindly export a list of duplicates from the Frog’s UI and dump it in a report without any thought.
As you may be giving them a list of URLs with issues to fix, but they aren’t actually causing issues, as they are correctly set to noindex.
But then again, you should never blindly rely on reports from any tools.
Tools give you an easy way to identify potential issues by gathering all the data. However, you need to use your own brain to decide what the best course of action is.
I often see people new to SEO making this mistake. Simply exporting issues from tools and adding them to reports without manually looking into the issues reported.
Take this example.
You might see in the Frog that there are 20 pages with duplicate titles.
You create a report and say “here are 20 URLs whose titles need re-writing” and just dump the data from the Frog.
However, there can be multiple reasons why these pages have duplicate titles and different fixes depending on the situation. e.g:
a. Duplicate URLs are being created by UTM parameters. So they should be canonicalised to the main URL.
b. There are sort pages from a category page, so they should probably be blocked in robots.txt
c. They are paginated pages, so they just need the page number added to the titles
d. They are actual duplicate pages, so probably need to be removed from the site.
e. It’s a duplicate page on a subdomain which is a development version of the site. It should be blocked from being accessed by users and search engines.
f. They are unique pages that just have the same titles. So they do indeed need unique titles written in this case.
So there we have 6 different fixes for URLs that could appear in the duplicate title filter in Frog.
Make use of tools, but don’t rely on them for making your recommendations.
Ignore Paginated URLs for Duplicate Filters.
This is ticked by default, but I like to know if paginated pages have duplicate titles, as I prefer them to have the page number added to the titles. So I untick this.
This means they will also show up in the Meta Description, Meta Keywords, H1 and H2 tabs duplication filters.
You can just ignore them when they do. It doesn’t matter if they duplicate these areas, as they are paginated pages, so it’s expected.
Always Follow Redirects
Always Follow Canonicals
These are unticked by default, I always tick them.
![]()
I tick both of these, as I want to ensure the Frog discovers all URLs on the site. There could be URLs that aren’t linked in the HTML of the code but are only linked to via a redirect, or in a canonical tag.
I want to know about such URLs, as this are another way URLs can be orphaned.
The majority of the time, if a page is important enough to index in Google, it should have links to it.
If I don’t tick this box, then URLs only found via a redirect or in a canonical tag would not be crawled or reported on.
![]()
Respect self referencing meta refresh.
I click this to ensure any URLs that have a self-referencing meta refresh get flagged as non-indexable in the UI.
Although a self referencing meta refresh wont actually won’t stop the page indexing, I want to see it easily flagged so I can investigate as to why the page is refreshing to itself.
Extract images from img srcset Attribute.
Google can crawl images implemented in the srcset attribute, so I tick this to ensure the Frog is extracting the same images Google would be. I can then check how they are optimised. (image file names, alt tags, size)
The following options are unticked by default and I also keep them that way. These settings are quite important, so I’ll explain the reasoning behind keeping them unticked:
Respect Noindex
Respect Canonicals
Respect next/prev

As I want to get a full picture of all the URLs on the site, whether they are indexable or not, I don’t want to tick the options above.
If I did tick them, it means any URLs set to noindex, or canonicalised to a different URL, would not be reported in the Frog.
This means I would have no idea of any pages set to noindex or canonicalised and we cannot check them to see if they are correctly set to be non-indexable.
In your work, you’ll often find examples where valid pages aren’t actually set to index in Google.
With the next/prev setting, as mentioned a few paragraphs above, I want to know what the titles for paginated pages are, so I keep this unticked.
Respect HSTS Policy.
With this setting ticked, even if a site has not redirected HTTP to HTTPS,
the Frog will still be redirected to the HTTPS.
As we want to check that HTTP has been permanently rejected to HTTPS, I leave this unticked.
Crawl Fragment Identifiers.
![]()
When ticking this, the Frog will consider URLs with hash fragments as separate URLs.
e.g
https://example.com/
https://example.com/#this-is-treated-as-a-separate-url/
However, these aren’t separate URLs and Google doesn’t count them as such either. Therefore we don’t care if these URLs have the same titles, h1s, meta, etc, because it’s a single URL.
All my advanced settings below:
Content
Duplicates

Only Check Indexable Pages for Duplicates.
Similar to the Ignore Non-indexable ULs for On-Page Filters previously, even if pages are currently set to noindex, I still want to know if they are duplicating content, in case they should be set to index.
So I untick this.
Enable Near Duplicates.
I tick this and set it around 80-90%. (This can vary depending if the site uses large sections of boilerplate plate content)
This will help identify pages that are duplicating large sections of content internally.
Spelling and Grammar
The majority of the time I will not turn on these options on for a few reasons:
- Most of the audits I do are technical/on-page in nature, not content audits
- The results can give false positives and there can be 10000s of issues to check through
- It seems to slooooooooooooooooow the Frog down massively!
If I was tasked with doing a content quality audit, then I would use these options.
Robots.txt
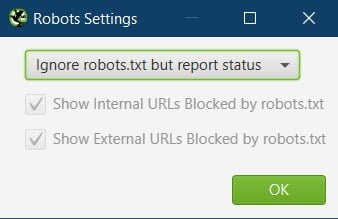
The default setting here is:
Respect robots.txt
But I have this set to:
Ignore robots.txt but report status
Again, the reason being I want the entire picture of the site’s pages, even if they are currently blocked in robots.txt.
This is so I can audit the pages which are blocked, make sure they aren’t blocked in error and report in the audit if the URLs need to be removed from robots.txt
Also, even if a page is blocked in robots.txt, it may still be indexed if Google found a link elsewhere, or it was indexed before being blocked.
So in some cases, I may want to remove URLs from robots.txt and deindex them using noindex or via canonicalisation.
CDNs
This setting is very useful if you are using a CDN for hosting your images which is not part of the domain you are crawling.
e.g.
https://cdn.not-your-domain.com/photos-of-cats.jpg
You can add the domain above, so Frog counts images on the other CDN domain as internal.
If you don’t set this and the site uses separate domain for images, you won’t be able to audit the images in Frog.
If you are are using your own subdomain for images
https://cdn.your-domain.com/photos-of-dogs.jpg
you don’t need to use this option.
(As long as you have ticked ‘Crawl all subdomains’ in the crawl configuration)
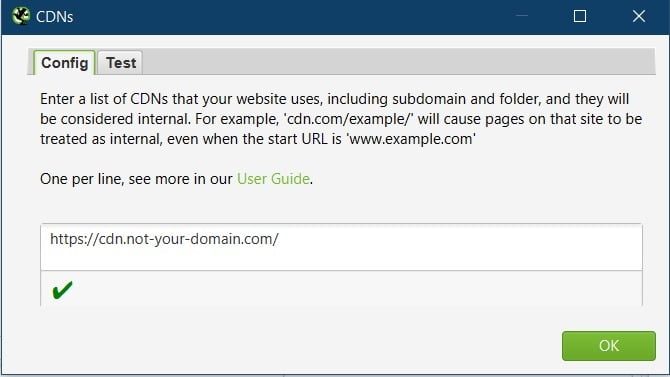
Speed
The default values for speed are:
Max Threads: 5
Limit URL/s: unticked
I’ll often increase the Max threads to 20 and see how the Frog and site get on. If your machine slows down drastically, you may need to decrease it.
If you notice lots of no response, 403 errors or 5xx errors coming back, it could be because you are crawling too fast.
Pause the crawl and reduce the Max threads down. Right-click the errors and try recrawling them.
You may need to limit the URL/s per second if the site is still having issues, or you are getting blocked.
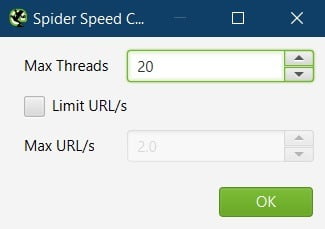
User-Agent
By default, the user agent used is ‘Screaming Frog SEO Spider’.
However, I set this to Googlebot (Smart Phone) for two reasons:
a. I want to understand how Google is viewing the site, so I use the same user agent.
There are instances where sites may change things depending on the user agent. This could be content, links, and redirects. It could be done for valid reasons, it could be done for black hat reasons, or because the site has been hacked.
Whatever the reason, I want to see exactly what Google is seeing.
b. Since Google has switched to mobile-first indexing, I want to see the mobile version of the code, as that is what Google will base their crawling, indexing and ranking on.
If you suspect there could be issues with parity between mobile and desktop code/content, you can check pages manually in a desktop browser and also crawl the site with user-agent set to Googlebot desktop, then compare crawls in Screaming Frog’s crawl compare feature.
API Access
Using the API access, I can enrich the crawl data with traffic data or data from backlink providers.
I include this data for several reasons:
a. Screaming Frog can extract all the URLs from GA/GSC, this includes URLs not found in the crawl. This is another way to find orphan URLs and help gather all known URLs on the site.
The Frog can then tell me which URLs are orphans and check all the elements for these pages.
b. The traffic data can help prioritise issues. When auditing a site you should prioritise all the issues identified. This becomes especially important when auditing large sites.
Why do we need prioritisation?
If for example, you report on 1000s of pages that need unique titles or 1000s of images that are missing alt tags, who is actually going to implement all these changes?
This is when SEOs can find that clients won’t implement all their changes.
If we have traffic data such as impressions, clicks, sessions, conversations or which URLs have backlinks, we can use that data to prioritise the pages to be fixed in the report.
This makes it more likely our recommendations will actually get implemented.
Also useful when auditing a site after a traffic drop in Google.
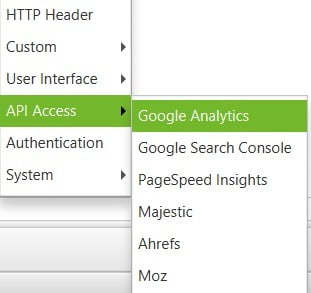
Google Analytics
User Account tab
When connecting the account, I’ll select organic traffic as the segment. As I want to see data for URLs indexed in Google only.
Date Range Tab
3 months is a good rule of thumb here. If you start taking it back years, you’ll most likely get loads of old pages that are 404s or redirected.
Metrics Tab
I usually just select Sessions. Depending on the type of site and may want to include other metrics such as Goals.
Dimensions Tab
I stick with ga:landingPagePath here.
As we are interested in the URLs that are indexed in Google, we are looking for the first URL in the user journey from organic search
General Tab
Match Trailing and Non-Trailing Slash URL & Match Uppercase & Lowercase URLs
I untick these, as I want to know if they could be causing duplicate issues (not redirected, or canonicalised)
Limit Max Results. It’s set to 100,000 by default. I’ll increase it if it’s a big site.
Crawl New URLs Discovered in Google Analytics
I tick these, as I want the Frog to discover orphan URLs indexed in Google so I can audit them
Google Search Console
Date Range Tab
Same as GA, 3 months is a good rule of thumb here.
Dimension Filter Tab
Keep as default, as I want as much data as possible.
General Tab
Same settings as GA here.
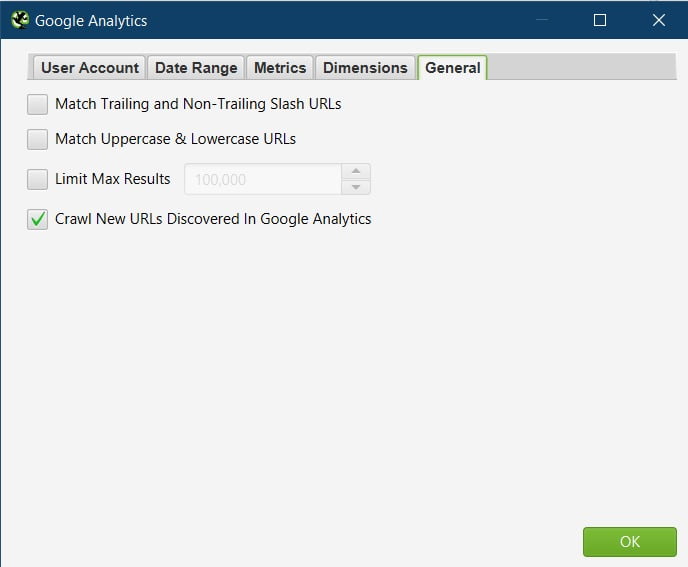
Ahrefs
Be default, Ahrefs API has the following metrics ticked:
URL (exact URL)
Backlinks
RefDomains
URL Rating
I change these to
URL (exact URL http + https)
Backlinks
RefDomains
URL Rating
I change this as I know it’s the same URL whether it’s HTTP or HTTPS. They should redirect/canonicalise to a single protocol, or I will recommend they do in the report if they don’t.
If I don’t have GA or GSC access, I’ll can also select Keywords and Traffic from Ahrefs here. This data can be used as a proxy for when missing traffic data.
Crawl Analysis
By default, all the options here are ticked and it’s set not to auto analyse at the end of the crawl.
I keep these settings, as if you’re crawling a massive site when it comes to analysing the crawl it can often take hours to complete (and sometimes crashes).
So before it starts analysing, you may want to have a look around the UI at the crawl data ensuring the crawl is complete with no errors to re-crawl.
You can set to analyse the crawl once you are happy with it and have saved it.

Saving Your Configuration
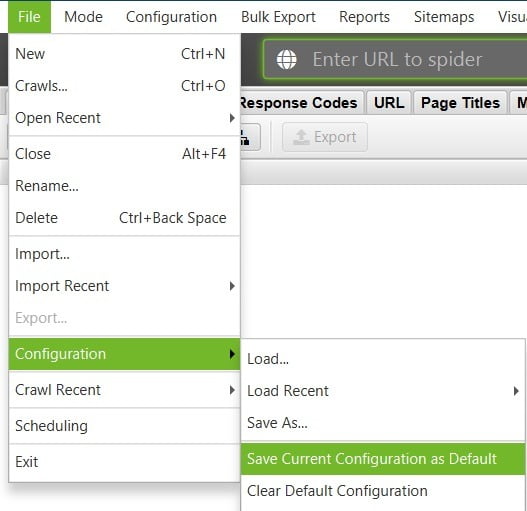
Once you have set all these settings, or your own preferred ones, don’t forget to save it! Otherwise, you will lose them on restart.
Go to file > Configuration > Save current configuration as default.
If you use Screaming Frog for lots of different tasks, you may want to save configurations to easily switch between different configurations.
Go to file > Configuration > Save As
Ok, there we go. If you’re a new user I hope you find this guide useful.
If you’re a long time user, I hope you found my insights interesting.
If you agree or disagree with my choices, or if you have any questions, let me know in the comments.
Thank you very much for the post. I need to do an in-depth audit and I have found these settings for Screaming Frog very useful.
Happy you found it useful René.
Great guide Max!
Ha I’ve seen “Web Light” in Search Console but never looked into it, wasn’t expecting to learn the answer in an article about SF! Wikipedia says it’s been discountined, another one for the Google Cemetery I think :-)
Thanks Martijn.
They were the first 2 things that popped into me head when thinking about HTTP Headers. I do most of my work in SE Asia where it’s more predominant so see it a lot.
I didn’t realise it was discontinued and after looking at wiki, it seems they haven’t announced it, but the URLs redirect. However checking in GSC, I’m still getting 10,000s impressions daily, so perhaps not fully.
Good article!
I would add that there are websites that make a reverse ip lookup to check if the user-agent is really Googlebot, and in that case, chrome user agent can help in case of crawling issues.
Hi Nadav,
Yes you’re right, spoofing Google user agent can result in being blocked quite often. I usually use the ‘Chrome for android’ user agent then, as most sites will be on mobile first index now so I want to see the mobile version.
Greetings from Ukraine! Thank you very much for such detailed instructions. You helped me find really useful settings that I hadn’t used before.
Glad you found it useful Eugene.
Stay safe my friend!
Thanks for this post. BTW, is there any special recipe for crawling JS sites?
You can check the rendering section of this guide for some tips on setting up to crawl JS sites. Then the rest of the settings are usually the same.
Thanks some great tips and insight for technical SEO here :) appreciate you creating it.
Glad you found it useful Cal.
Thanks for sharing. is there any way to crawl angular websites? it seems Screaming frog and other crawlers cant crawl theses websites.
Hi Rad,
Have you already tried changing the rendering setting to JavaScript? https://technicalseo.consulting/the-best-screaming-frog-settings-for-site-audits/#Rendering_Tab
Congratulations for the post. I liked so much to notice that to follow nofollow liks can be useful. Very interesting content.
Glad you found it useful.
Great post!
I just wish you had shared your config file, since I trust your settings blindly! :)
Thank you for this great article
Thanks, although best to use the settings here as a guide, but then adjust them as needed, as may need slightly different settings for each site.
[…] files. For that reason, I typically follow the philosophy and recommendations espoused by Max Peters’s Screaming Frog settings guide–one of my favorite Screaming Frog resources–and turn on all of URL discovery settings I […]